FUSION: Full-Body Unified Motion Prior for Body and Hands via Diffusion
Conference on Computer Vision & Pattern Recognition, Findings Track (CVPR), 2026
Enes Duran1,2, Nikos Athanasiou1, Muhammed Kocabas1,3, Michael J. Black1,3, Omid Taheri1
1Max Planck Institute for Intelligent Systems
2Eberhard Karls University of Tübingen
3Meshcapade GmbH
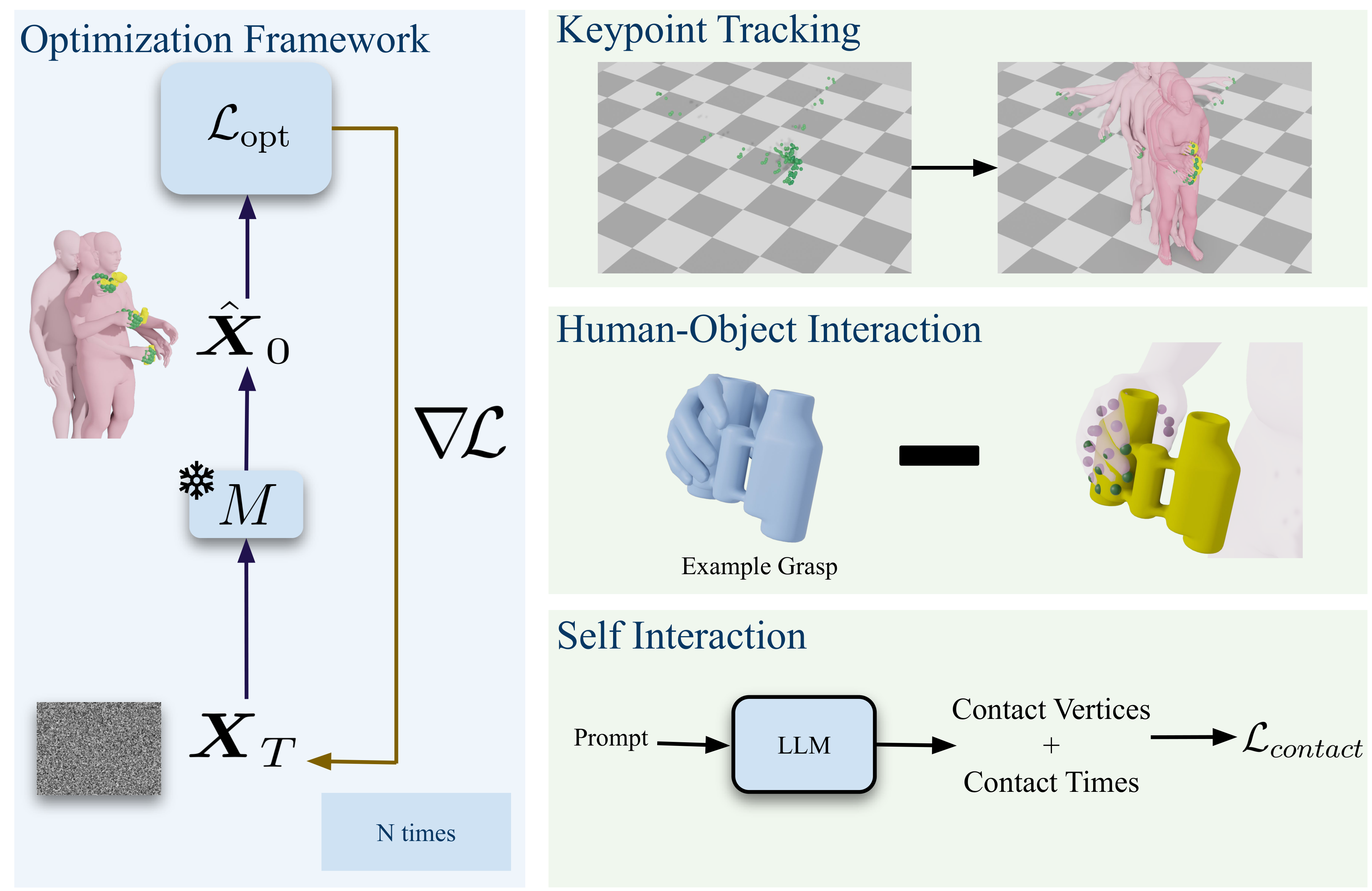
Abstract
Hands are central to interacting with our surroundings and conveying gestures, making their inclusion essential for full-body motion synthesis. Despite this, existing human motion synthesis methods fall short: some ignore hand motions entirely, while others generate full-body motions only for narrowly scoped tasks under highly constrained settings. A key obstacle is the lack of large-scale datasets that jointly capture diverse full-body motion with detailed hand articulation. While some datasets capture both, they are limited in scale and diversity. Conversely, large-scale datasets typically focus either on body motion without hands or on hand motions without the body. To overcome this, we curate and unify existing hand motion datasets with large-scale body motion data to generate full-body sequences that capture both hand and body. We then propose the first diffusion-based unconditional full-body motion prior, FUSION, which jointly models body and hand motion. Despite using a pose-based motion representation, FUSION surpasses SOTA skeletal control models on the Keypoint Tracking task in the HumanML3D dataset and achieves superior motion naturalness. Beyond standard benchmarks, we demonstrate that FUSION can go beyond typical uses of motion priors through two applications: (1) generating detailed full-body motion including fingers during interaction given the motion of an object, and (2) generating Self-Interaction motions using an LLM to transform natural language cues into actionable motion constraints. For these applications, we develop an optimization pipeline that refines the latent space of our diffusion model to generate task-specific motions. Experiments on these tasks highlight precise control over hand motion while maintaining plausible full-body coordination.
Video
Qualitative Results
Keypoint Tracking
Self-Interaction




Human-Object Interaction
Citation
@InProceedings{Duran_2026_WACV,
author = {Duran, Enes and Kocabas, Muhammed and Choutas, Vasileios and Fan, Zicong and Black, Michael J.},
title = {FUSION: Full-Body Unified Motion Prior for Body and Hands via Diffusion},
booktitle = {Proceedings of the IEEE/CVF of Computer Vision and Pattern Recognition (CVPR)},
month = {xx},
year = {2026},
pages = {xx}
}